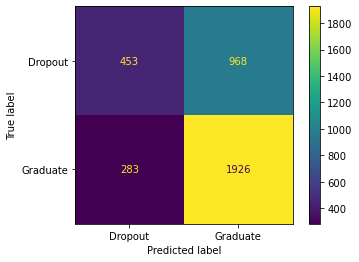
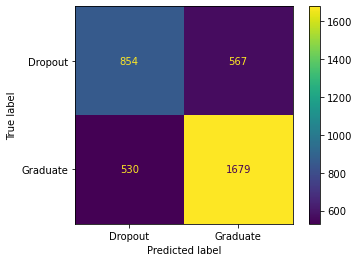
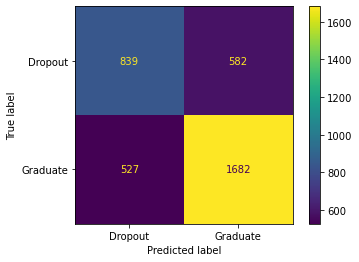
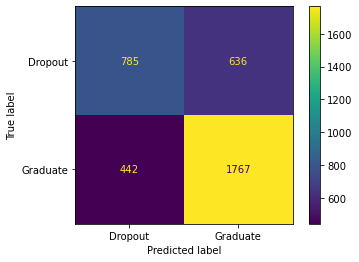
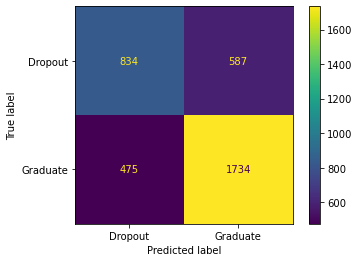
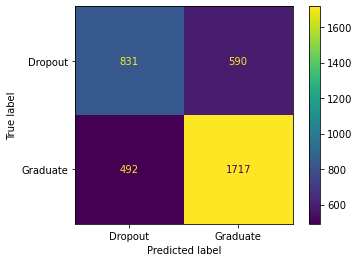
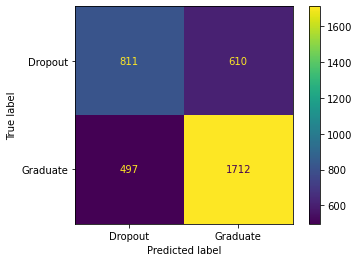
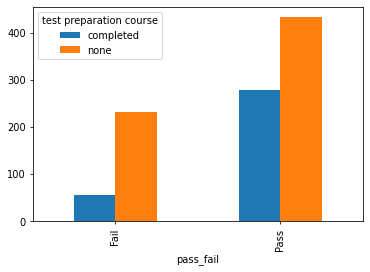
This data was given to my team and I from the ABA
The goals of the ABA are to promote the platform to low-income clients, recruit new attorneys, train these attorneys, and improve the overall user experience. Our overall goal is to relate the category of the client’s question to their age, geographic region, and ethnic identity to detect trends or patterns. This can help train attorneys to be more efficient in their responses. Another goal is to identify categories that have areas of need in terms of response rates. By identifying these areas of need, we can offer better recommendations as to where the ABA should allocate its resources to maximize efficiency.
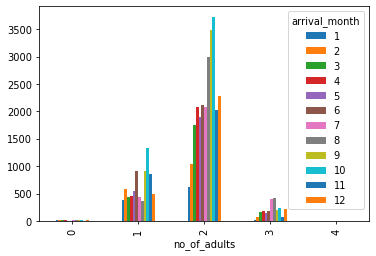
This data contained a lot of different information that we could use to create our analysis, We condensed the amount of different data by separating states in regions to get a better look and create better visualizations about the clients. My team dedicated most of our time to recruiting and preparing new attorneys. To do so we looked at the type of clients in certain areas and the questions these clients were asking in certain areas. Some of the most asked questions included, Houses and Homelessness, Family and Children, and Consumer Financial. Using some statistical techniques we were able to create some visualizations to help show lawyers where they should spend the majority of their time. The first one we created was a line graph that shows the questions asked by year.

In this graph, as I said above you can see the dramatic increase in Family and Children, Housing and Homelessness, and in this case, Other which were topics we did not have access to.

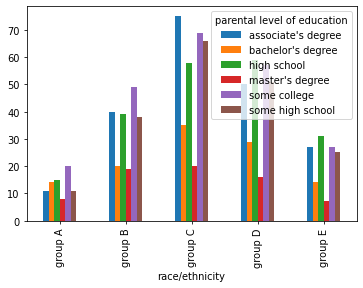
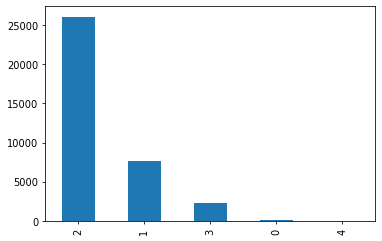
This next graph was created to show lawyers what cases are most popular in their location. The three main ones were obviously present in all locations but we made this for the exact reason of spotting things such as the individual rights were predominantly shown in the southwest region.

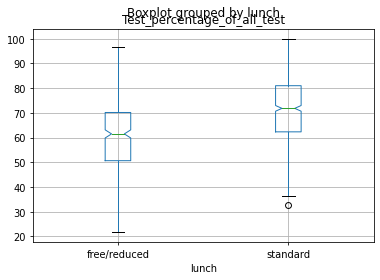
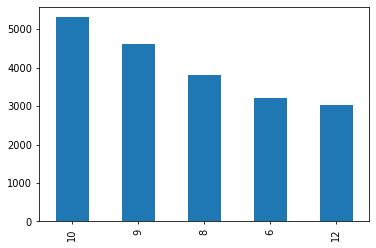
This graph shows the average duration of cases by category of case, so for the first time in one of our plots Family and Children were not the highest and neither was Housing and Homelessness. We found that Juvenile cases are the cases with the longest completion time followed by Consumer Financial Questions. This could be because it takes a lot longer for things to get approved in a Juvenile involved case, which shows lawyers that they need to prepare in advance that certain cases can and will take longer than others.

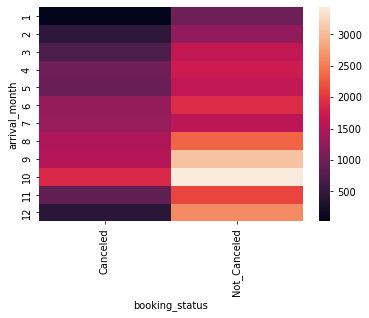
The final graph we made was the percentage of questions unanswered by category, We made this graph to show lawyers where they could find the most available and needed work. Back at the top again was the Juvenile category which had around 42% of cases left unanswered. Followed by Individual Rights, which we thought could be because it is a risk-taking one of these cases because lawyers know how much harder it is to legally do things while representing a juvenile, and representing rights cases can also be a lot harder than an Education case in some instances.
One potential solution to improve the quality of legal assistance and client understanding is to provide comprehensive training programs for new attorneys. By equipping attorneys with the necessary skills and knowledge, they can better serve their clients and provide more effective legal representation.
As for the data analysis, our findings suggest that there is a high demand for Family and Children attorneys, as evidenced by the high number of unanswered questions in that category. If the data were to be resampled in the future, we would expect to see a decrease in the number of unanswered questions in this category due to the increased availability of qualified attorneys.
Additionally, we found that the juvenile category had the highest number of unanswered questions, which we attribute to the lengthy nature of juvenile trials. To address this issue, it may be beneficial to streamline the juvenile court process or allocate additional resources to improve efficiency and reduce the time it takes to resolve these cases. By training attorneys to specialize in these categories the ABA will be able to increase access to such a critical resource.